






 Nästa uppdatering av Arm:s 64-bitarsarkitektur ArmV8-A kommer att stödja Googles numeriska format Bfloat16. Det används i artificiella neuronnät. I och med att även Arm nu ger det sitt stöd, blir det i praktiken en standard.
Nästa uppdatering av Arm:s 64-bitarsarkitektur ArmV8-A kommer att stödja Googles numeriska format Bfloat16. Det används i artificiella neuronnät. I och med att även Arm nu ger det sitt stöd, blir det i praktiken en standard.
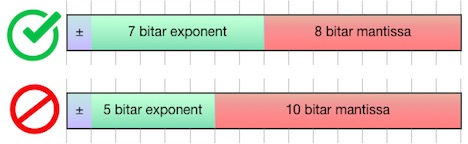
Storlek är viktigare än precisionI tredje generationen av sin neuronprocessor TPU introducerade Google flyttalstypen Bfloat16, som använder åtta bitar för exponent och sju för mantissa. Ett FP16 (16-bitars flyttal) i standardformat använder tio bitar för mantissa och fem bitar för exponent. Men i artificiella neuronnät kan man kompromissa med precisionen när det gäller att representera de parametrar som kallas vikter och bestämmer vilken funktion ett neuronnät beräknar. Ett FP32 (32-bitars flyttal) har betydligt högre precision – 23 bitar – men samma exponent som BF16, vilket gör dem lätta att konvertera när FP32 exempelvis använts för att beräkna mellanresultat. Armv8-A introducerar stöd för flyttalstypen Bfloat16 i alla sina numeriska paket: SVE (Scalable Vector Extension), AArch64 Neon (64-bit SIMD) och AArch32 Neon (32-bit SIMD). En del instruktioner mixar BF16 och FP32, som BFDOT som ger skalärprodukten av två par av BF16 som en FP32. Operationen som konverterar en FP32 till BF16 heter BFCVT |
För en månad sedan nämnde vi att Intel var i färd med att styra över från ett neuronnätsanpassat flyttalsformat kallat Flexpoint, till ett annat kallat Bfloat16 (”brain floating point”). Också neuronprocessorer från Wave Computing, Habana Labs, and Flex Logix använder Bfloat16, också känt som BF16.
Nu rapporterar Arm att det kommer att följa efter.
Det är inte varje dag det introduceras stöd för ett nytt numeriskt format i en generell processor, som Arm nu gör. Det demonstrerar vilket genomslag maskininlärning fått. Det är härmed lika självklart i en generell cpu att ha stöd för neuronnät, som att ha stöd för grafik.
Enligt Arm dubblerar BF16 genomströmningen och halveras minnesåtgången jämfört med att använda det numeriska formatet FP32.
Om ett neuronnät inte kan konverteras från FP32 till BF16 helt enkelt genom att droppa de minst signifikanta bitarna i vikterna, är det en indikator på att nätet inte är robust. Tänk såhär: indata till neuronnäten kommer från en brusig verklighet. Det bruset borde inte påverka vad neuronnätet anser att exempelvis ett foto föreställer. En mantissa på sju bitar ger 128 nivåer motsvarande en onoggrannhet under en halv procent.
BF16 skapades för att stödja artificiella neuronnät. Men nu när det existerar och får stöd, undersöker numeriker om det kan höja prestanda även i traditionella tillämpningar.
Att BF16 får en de factostandard innebär inte automatiskt att det är oproblematiskt att flytta ett neuronnät från en plattform till en annan. Det finns ingen standard för hur operationer ska bete sig, exempelvis i vilken ordning operander ska appliceras, vilket betyder att resultatet av beräkningar ändå kan skilja sig åt. Detta är dock inget nytt problem utan gäller även exempelvis FP32.
Det viktigaste namn som inte deklarerat stöd för BF16 är Nvidia, vars grafikkort dominerar för neuronnätsberäkningar inom moln och andra tunga tillämpningar.































