






 Amerikanska Cerebras nya arkitektur kan teoretiskt skalas upp till en storlek motsvarande en människohjärna. Knepet är att lagra nätets parametrar, vikterna, utanför jättechipet.
Amerikanska Cerebras nya arkitektur kan teoretiskt skalas upp till en storlek motsvarande en människohjärna. Knepet är att lagra nätets parametrar, vikterna, utanför jättechipet.
På mässan Hot Chips igår presenterade jättechiptillverkaren Cerebras en ny skräll: för att kunna arbeta mot ännu större nät har Cerebras börjat skifta delar av neuronnäten in och ut ur chipet.
Är det inte samma knep som Cerebras konkurrenter alltid använt?
Jo. De har klippt upp neuronnät och skiftat nätets parametrar in och ut för att kunna arbeta med nät som i sin helhet ryms på Cerebras jättechip. Men nu erbjuder Cerebras en liknande möjlighet och kan därmed arbeta mot nät som är ytterligare hundra gånger större.
Den nya arkitekturen tillåter nät med upp till 120 biljoner vikter. Något som är fascinerande med den siffran är att en fullvuxen människa har någonstans mellan 100 och 1000 biljoner synapser – som är motsvarigheten till dessa vikter.
Biljon heter ”trillion” på engelska och miljard heter ”billion”, om du undrar över översättningen.
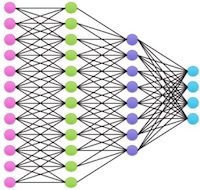
Artificiella neuronnät är förenklade modeller av biologiska hjärnor, och idag går det alltså att praktiskt hantera artificiella neuronnät som är i samma skala som människohjärnor. Inga jämförelser i övrigt.
Cerebras är inte ensamt om att nosa på artificiella neuronnät i den här storleken. Microsoft kan använda 512 stycken NVIDIA V100-kretsar för att träna ett neuronnät med 20 biljoner vikter. Arkitekturen kallas Zero-Infinity och ska vara skalbar till ”hundratals biljoner” vikter.
Det största praktiskt använda neuronnät Elektroniktidningen lyckas googla upp är en språkmodell kallad GPT-3 som ”bara” använder 175 miljarder parametrar. Det tog fyra månader att träna, på tusen grafikprocessorer. Men som Cerebras påpekar har neuronnäten under de tre senaste åren vuxit med en magnitud per år.
Cerebras nya arkitektur kallas Weight Streaming och använder ett minnessystem som heter MemoryX. Hårdvaran i övrigt är samma CS-2-system med samma chip, WSE-2, som Cerebras presenterade i somras.
 |
|
Ett ensamt CS-2-skåp med minnessystem och allt, ska rymma ett neuronnät med 120 biljoner vikter |
Cerebras använder ett eget interconnect kallat SwarmX som kopplar samman CS-2-system. Upp till 192 stycken CS-2-system kan kopplas samman med enligt Cerebreas linjär uppskalning av träningsprestandan.
Denna uppskalning av träningsprestanda på stora nät, är vad den initierade sajten The Next Platform tycker är det mest intressanta med Cerebreas presentation.
Under träning strömmas vikterna in från det externa minnet via SwarmX till jättechipet, som räknar ut hur vikterna ska förändras, och sedan strömmar tillbaka dessa deltavärden till det externa minnet.
Cerebras presenterade ytterligare en nyhet som kanske är praktiskt viktigare på kort sikt: högre prestanda på träning av så kallade glesa neuronnät, det vill säga neuronnät där många vikter är noll.
Det har visat sig att det går att kraftigt beskära neuronnät utan att de tappar i precision. I teorin ger detta betydligt färre beräkningar – men inte i praktiken så länge som hårdvaran är anpassad för att räkna på kompletta nät.
Nyckeln till Cerebras prestanda är dess jättechip som är 57 gånger större än världens näst största chip. Cerebras är såvitt känt fortfarande ensamt om att ha lyckats tillverka ett chip av en komplett kiselskiva, där alla andra styckar upp den tallriksstora kiselskivan i 100–1000 små rektanglar. Chipet kostar därefter – ett par, tre miljoner dollar styck.
Chipet i sig släpptes i somras i sin andra generation WSE2 i 7 nm med 2,6 biljoner transistorer och 40 Gbyte SRAM.
































