







 Nu finns en asic hårdkodad för en specifik LLM. Prestanda ska vara tio gånger bättre än du kan erhålla för samma LLM i dagens AI-datacenter. Det är första chipet från kanadensiska uppstarten Taalas.
Nu finns en asic hårdkodad för en specifik LLM. Prestanda ska vara tio gånger bättre än du kan erhålla för samma LLM i dagens AI-datacenter. Det är första chipet från kanadensiska uppstarten Taalas.
Vi hörde första gången talas om Taalas för två år sedan när de samlat ihop en investering på 50 miljoner dollar. När de nu kan visa upp ett fungerande chip har de fått ytterligare 169 miljoner.
LLM:en de huggit i kisel är Llama 3.1 8B. Den är fri, liksom alla Metas Llama-modeller. Llama har blivit något av en standard inom fria LLM:er och har utmålats som ett hot mot kommersiella modeller.
Llama 3.1 8B har 8 miljarder parametrar. Taalas planerar att lansera ytterligare två asicar i år. Nästa ska ha 20 miljarder parametrar.
Enligt Meta används Llama-modeller inom bland annat forskning, utbildning, videokommunikation och medicin. Om du har mindre än 700 miljoner användare är Llama gratis.
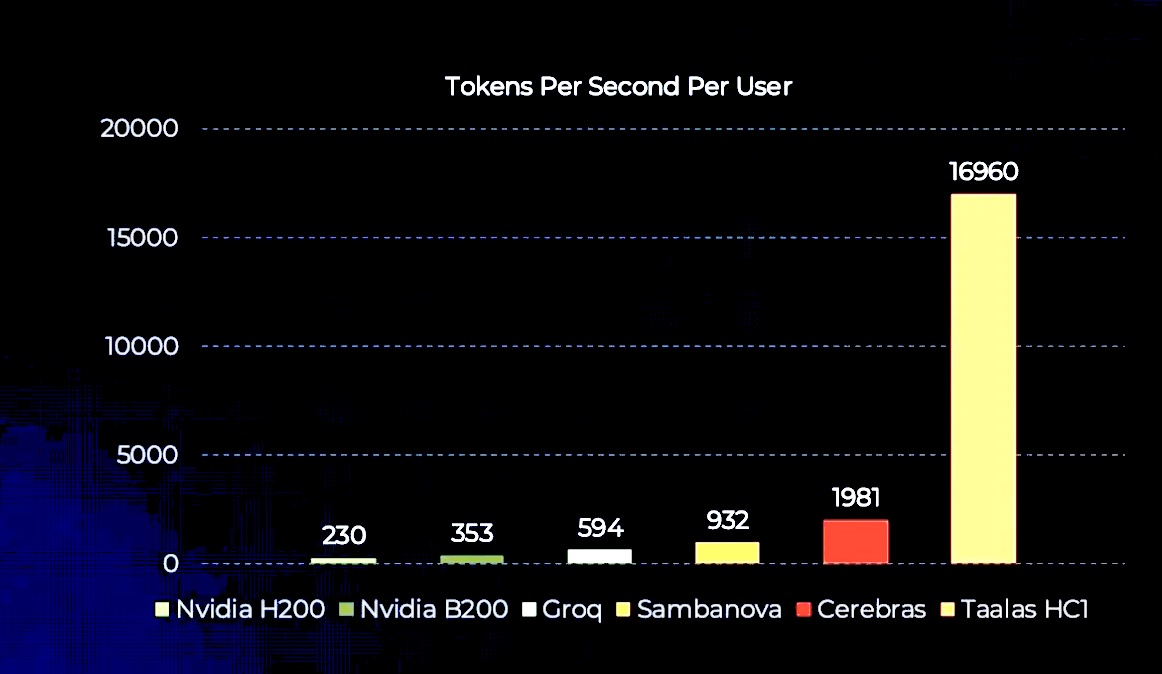 Det tar Taalas och TSMC två månader att implementera en asic för en LLM. Prestandavinsten för asicen blir i Llama 3.1 8B:s fall nära tio gånger jämfört med ”nuvarande topprestanda”. Till och med Cerebras tallriksstora chip ligger i lä.
Det tar Taalas och TSMC två månader att implementera en asic för en LLM. Prestandavinsten för asicen blir i Llama 3.1 8B:s fall nära tio gånger jämfört med ”nuvarande topprestanda”. Till och med Cerebras tallriksstora chip ligger i lä.
Taalas hör hemma i generativ AI:s vagga, Toronto. Bolagets tre grundare arbetade nyss på kanadensiska Risc V-projektet Tenstorrent. Bland grundarnas tidigare arbetsgivare finns Altera, ATI, AMD, Nvidia och Google. Det krävdes ett team på 24 personer för att ta fram denna företagets första asic.
Detaljerna kring arkitekturen är hemliga. Vikter och modeller kodas i mask-ROM som samverkar med SRAM för bland annat KV-cache och anpassningar. Varje transistor i mask-ROM-delen kan lagra flera bitar och samtidigt utföra multiplikationer.
Att anpassa chipet till en ny modell kräver ändringar i metallager snarare än en total omdesign. Själva träningen av en LLM ska som jämförelse kosta hundra gånger mer än att utveckla asicen.
Chipet levereras på ett PCI Express-kort. Det förbrukar cirka 200 watt.
Första generationens chip tillverkas i 6 nm-process, har en yta på 815 mm² och innehåller 53 miljarder transistorer.
Senare under året planerar Taalas att möjliggöra pipeline-parallellism över flera kort.
Här kan du prata med Taalas chattbott Jimmy.


































