En heterogen beräkningsplattform som är skalbar, gör AI-inferenser och kan programmeras utan hårdvarukunskaper. Möt Versal, Xilinx nya systemkrets som ska ta plats i allt från 5G-basstationer till självkörande fordon och datahallar.
En heterogen beräkningsplattform som är skalbar, gör AI-inferenser och kan programmeras utan hårdvarukunskaper. Möt Versal, Xilinx nya systemkrets som ska ta plats i allt från 5G-basstationer till självkörande fordon och datahallar.
I Versal är de klassiska uppslagstabellerna bara en av alla pusselbitar i vad som kallas Acap, adaptive compute acceleration platform.
– Acap är ingen FPGA, den är ett kvantsprång. Den är skalbar och heterogen och går att programmera som mjukvara och hårdvara, säger företagets vd Victor Peng.
Utvecklingen har pågått i fyra år och kostat över en miljarder dollar, men så ska Versal klara av det mesta från filhållning i ADAS-system till att styra antennloben i en 5G-basstation och accelerera algoritmer i datacenter.
När Xilinx lättade lite på förlåten i februari var det lätt att uppfatta Versal, eller Everest som var kodnamnet under utvecklingsarbetet, som en förbättrad Zynq – Xilinx systemkrets med processorkärnor, logikblock och snabb kommunikation till omvärlden.
Vissa bitar känns igen, bland annat sexvägslogiken. Som brukligt med en ny generation är den trimmad. Denna gång för att bli kompaktare plus att minnet kan konfigureras på ett flexiblare sätt och dessutom arrangeras hierarkiskt. Kopplingen mellan logiken och minnet är förbättrad för att minska fördröjningarna.
De hårda Arm-kärnorna är numera dubbla Cortex-A72 plus att det finns två R5 för realtidsuppgifter
Hela uppstartsförloppet har ändrats. I Zynq startade processorn först, sedan laddades FPGA-delen via en bitström på klassiskt maner.
I Versal finns en ny så kallad bootmanager vilket gör att kretsen startar på ungefär samma sätt som en processor. Den kan också hantera uppgifter som power management och göra omkonfigureringar under drift, en uppgift som går åtta gånger snabbare numera.
Ett helt nytt block är den egenutvecklade AI-processorn som används för att dra slutsatser om vilken typ av objekt indata beskriver.
Processorn är skalbar och varje kärna kan betraktas som en 512 bitar bred vektorpipeline som utför en instruktion på flera data parallellt. Om data är åtta bitar (INT8) kan varje block bearbeta 64 stycken parallellt med en och samma instruktion, så kallad SIMD, Single Instruction Multiple Data.
Dessutom är arkitekturen av typen Very long instruction word (Vliw) där man förutom SIMD-instruktionen också laddar in två skalärer, två loadinstruktioner liksom en instruktion för store och en för stream.
Förutom att AI-processorn är upp till åtta gånger snabbare än motsvarande implementation i programmerbar logik kan effektförbrukningen i bästa fall halveras plus att fördröjningarna är korta.
– Jämfört med en serverprocessor är den 43 gånger snabbare. Den är dubbelt så snabb som en grafikprocessor. Dessutom kan den göra annat än bara inferenser.
Jämförelserna gäller för batchjobb som inte är tidskritiska. Om man kräver svar inom 2 ms har Versal ett övertag på åtta gånger och serverprocessorn klarar inte ens uppgiften.
Tittar vi på DSP-blocken är även de nya och optimerade för flyttal med hög precision där det är krav på kort tidsfördröjning. Precis som tidigare ligger de utspridda i logiken.
För att allt ska blir praktiskt användbart har Xilinx tagit fram en rad verktyg men också IP-block, bibliotek, middleware och ramverk som gör att man kan använda konventionella designflöden.
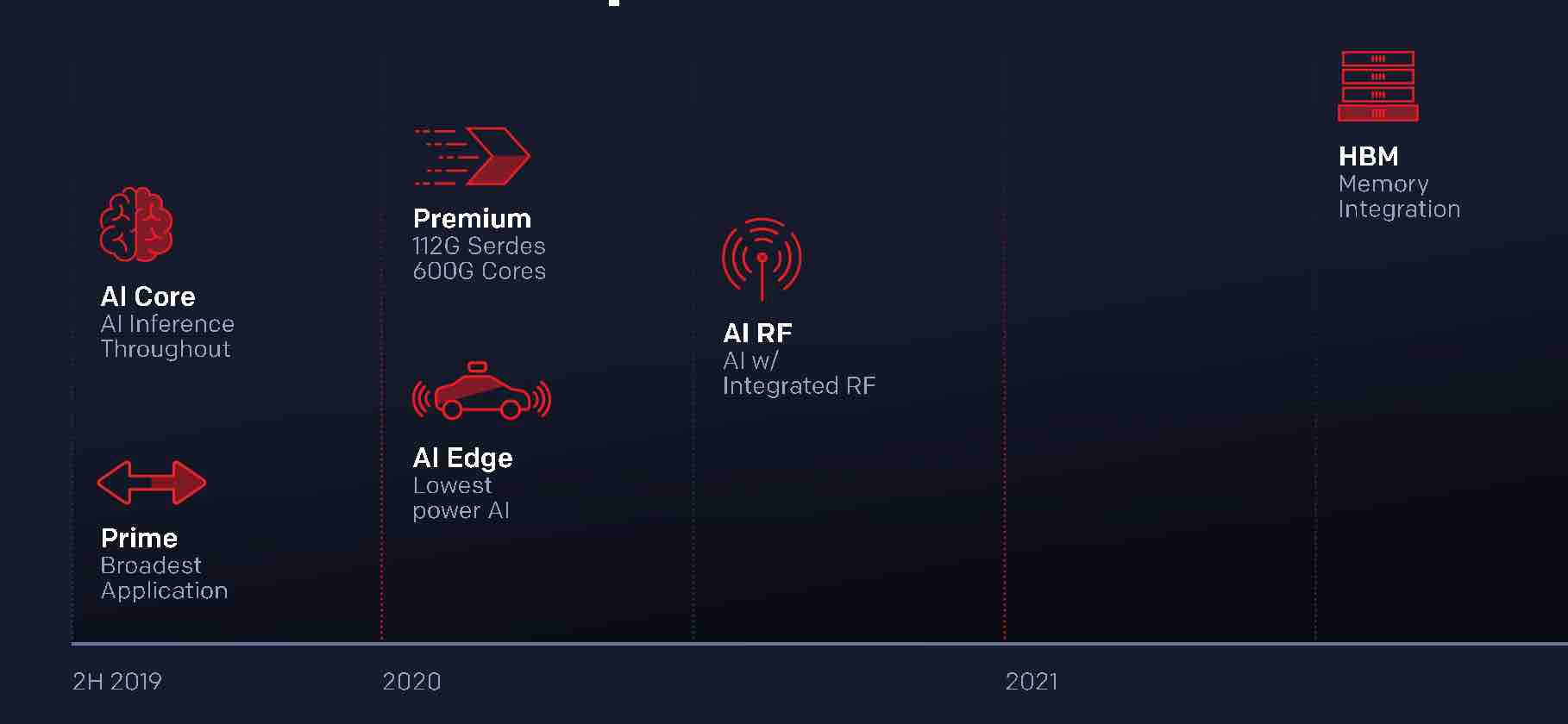
 Versal kommer i sex modeller varav de två första, AI Core och Prime lanseras nu för att komma i produktion om ett år. Övriga modeller släpps successivt under de kommande åren.
Versal kommer i sex modeller varav de två första, AI Core och Prime lanseras nu för att komma i produktion om ett år. Övriga modeller släpps successivt under de kommande åren.
Programmeringen kan göras på olika sätt. Längst ned finns den klassiska FPGA-programmeraren som förstår hårdvaran. Utgår man från algoritmerna kan programmeringen göras utan att grotta ner sig i detaljerna via Tensorflow, Caffe, mxnet eller andra ramverk.
För inbyggnadstillämpningar kan man utgå från operativsystem som Linux eller FreeRtos.
Av de två modeller som lanseras nu har Versal AI Core mest beräkningskraft och ger kortast fördröjningar. Med möjligheten att styra kapaciteten i inferenser relativt annan beräkningskapacitet är den tänkt för molntillämpningar, nätverkstjänster och ADAS-funktioner.
Den kommer i fem varianter med 128 till 400 AI-kärnor. Dessutom finns en tvåkärnig Arm Cortex-A72, en tvåkärnig Cortex-R5, 256 kByte minne med felkorrigering, över 1900 DSP-block som optimerats för flyttal med hög precision.
Vidare finns upp till 1,9 miljoner logikceller plus 130 Mbit UltraRAM, upp till 34 Mbit block-RAM och 28 Mbit distribuerat RAM och 32 Mbit av den nya typen Accelerator RAM som kan nås direkt från vilken av alla beräkningsmotorer och är unik för Versal AI-familjen.
För kommunikation finns PCIe Gen4 8-lane och 16-lane och det är förberett för CCIX-gränssnitt (Cache Coherent Interconnect for Accelerators). Vidare finns energioptimerade Serdesblock för 32 Gbit/s, upp till fyra minneskontrollers för DDR4, upp till fyra MAC-block för Ethernet med olika hastigheter liksom 650 generella in- och utgångar som exempelvis kan användas till sensorer som kameror plus diverse andra in- och utgångar.
Allt är kopplat till den interna bussen som även den är nyutvecklad och kan hantera upp till 28 portar som kan vara endera master eller slav. Bussen som kallas network-on-chip (NoC) är programmerbar och klarar terabithastighet. Det blir därmed enkelt att sätta upp en förbindelse mellan exempelvis ett minne och en beräkningsenhet. Dessutom går det att segmentera för att minska sårbarheten vid attacker.
Versal Primefamijen saknar AI-processon och är tänkt för en rad tillämpningar på många marknader. Familjen innehåller nio medlemmar med en tvåkärnig Arm Cortex-A72, en tvåkärnig Cortex-R5, 256 kbyte minne med felkorrigering, över 4000 DSP-block som optimerats för flyttal med hög precision och kort fördröjning. Vidare finns över två miljoner logikceller plus mer än 200 Mbit UltraRAM, mer än 90 Mbit block-RAM och 30 Mbit distribuerat.
För kommunikation finns PCIe PCIe Gen4 8-lane och 16-lane och det är förberett för CCIX-gränssnitt (Cache Coherent Interconnect for Accelerators). Vidare finns effektoptimerade serdesblock för 32 Gbit/s liksom serdesblock för 58 Gbit/s med PAM4.
De första två familjerna är enchipslösningar som tillverkas i TSMC:s 7 nm FinFET-process. Det gäller även den kommande rf-modellen medan andra varianter ska nyttja TSMC:s byggsätt Cowos där en bärare i kisel gör det möjligt att kombinera flera chip i samma kapsel.
Exakt vad kretsarna kommer att kosta är inte officiellt men spannet uppges vara stort. Xilinx siktar på att de billigaste ska användas av fordonsindustrin för ADAS-funktioner.